from scholarly_infrastructure.rv_args.nucleus import RandomVariable, experiment_settingfrom optuna.distributions import IntDistribution, FloatDistribution, CategoricalDistributionfrom typing import Optional, Union
Exported source
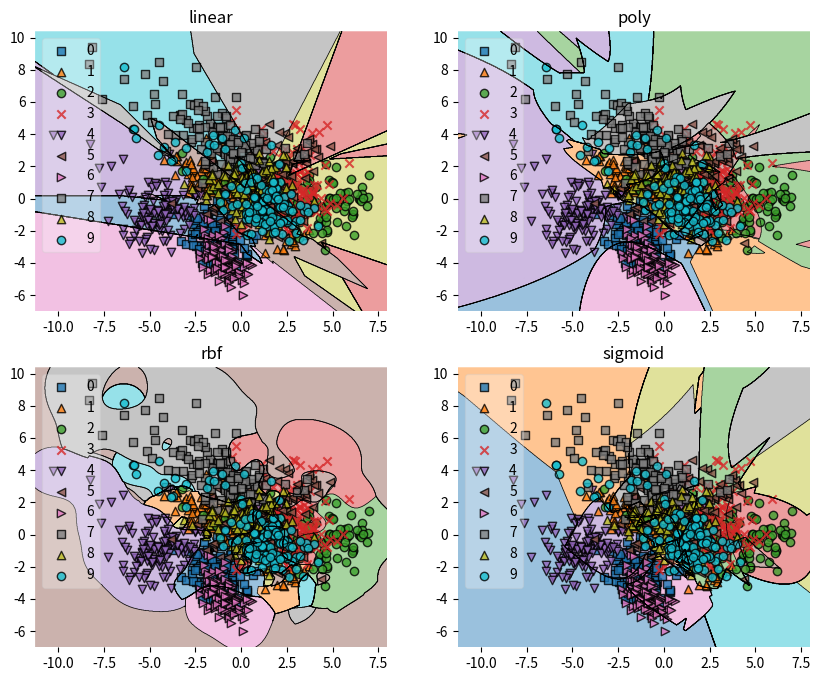
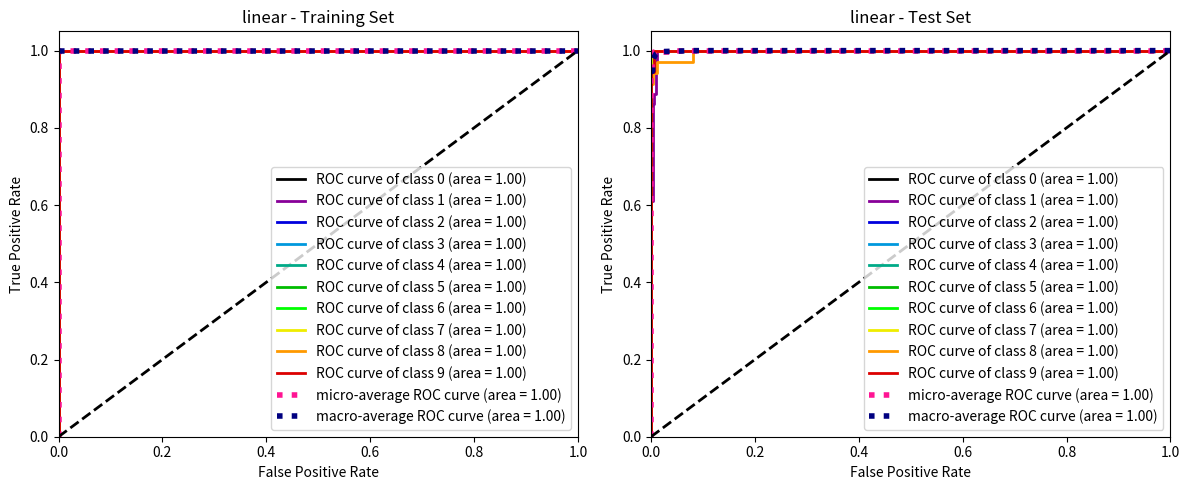
@experiment_settingclass SupportVectorClassifierConfig:# 惩罚系数 C C: float=~RandomVariable( default=1.0, description="Regularization parameter. The strength of the regularization is inversely proportional to C.", distribution=FloatDistribution(1e-5, 1e2, log=True) )# 核函数类型 kernel: str=~RandomVariable( default="rbf", description="Kernel type to be used in the algorithm.", distribution=CategoricalDistribution(choices=["linear", "poly", "rbf", "sigmoid","precomputed" ]) )# 多项式核函数的度数 degree: int=~RandomVariable( default=3, description="Degree of the polynomial kernel function ('poly').", distribution=IntDistribution(1, 10, log=False) )# 核函数系数 gamma gamma: Union[str, float] =~RandomVariable( default="scale", description="Kernel coefficient for 'rbf', 'poly' and 'sigmoid'.", distribution=CategoricalDistribution(choices=["scale", "auto"]) # 可以添加浮点数分布视需求 )# 核函数独立项 coef0 coef0: float=~RandomVariable( default=0.0, description="Independent term in kernel function. It is significant in 'poly' and 'sigmoid'.", distribution=FloatDistribution(0, 1) )# 收缩启发式算法 shrinking: bool=~RandomVariable( default=True, description="Whether to use the shrinking heuristic.", distribution=CategoricalDistribution(choices=[True, False]) )# 是否启用概率估计 probability: bool=~RandomVariable( default=False, description="Whether to enable probability estimates. Slows down fit when enabled.", distribution=CategoricalDistribution(choices=[True, False]) )# 停止准则的容差 tol tol: float=~RandomVariable( default=1e-3, description="Tolerance for stopping criterion.", distribution=FloatDistribution(1e-6, 1e-1, log=True) )# 内核缓存的大小(MB) cache_size: float=~RandomVariable( default=200, description="Specify the size of the kernel cache (in MB).", distribution=FloatDistribution(50, 500, log=False) )# 类别权重 class_weight class_weight: Optional[Union[dict, str]] =~RandomVariable( default=None, description="Set C of class i to class_weight[i]*C or use 'balanced' to adjust weights inversely to class frequencies.", distribution=CategoricalDistribution(choices=[None, "balanced"]) )# 是否启用详细输出 verbose: bool=~RandomVariable( default=False, description="Enable verbose output (may not work properly in a multithreaded context).", distribution=CategoricalDistribution(choices=[True, False]) )# 最大迭代次数 max_iter: int=~RandomVariable( default=-1, description="Hard limit on iterations within solver, or -1 for no limit.", distribution=IntDistribution(-1, 1000, log=False) )# 决策函数形状 decision_function_shape: str=~RandomVariable( default="ovr", description="Whether to return a one-vs-rest ('ovr') decision function or original one-vs-one ('ovo').", distribution=CategoricalDistribution(choices=["ovo", "ovr"]) )# 是否打破决策函数平局 break_ties: bool=~RandomVariable( default=False, description="If True, break ties according to the confidence values of decision_function when decision_function_shape='ovr'.", distribution=CategoricalDistribution(choices=[True, False]) )# 随机种子 random_state random_state: Optional[int] =~RandomVariable( default=None, description="Controls random number generation for probability estimates. Ignored when probability=False.", distribution=IntDistribution(0, 100) # 根据需求设置范围 )
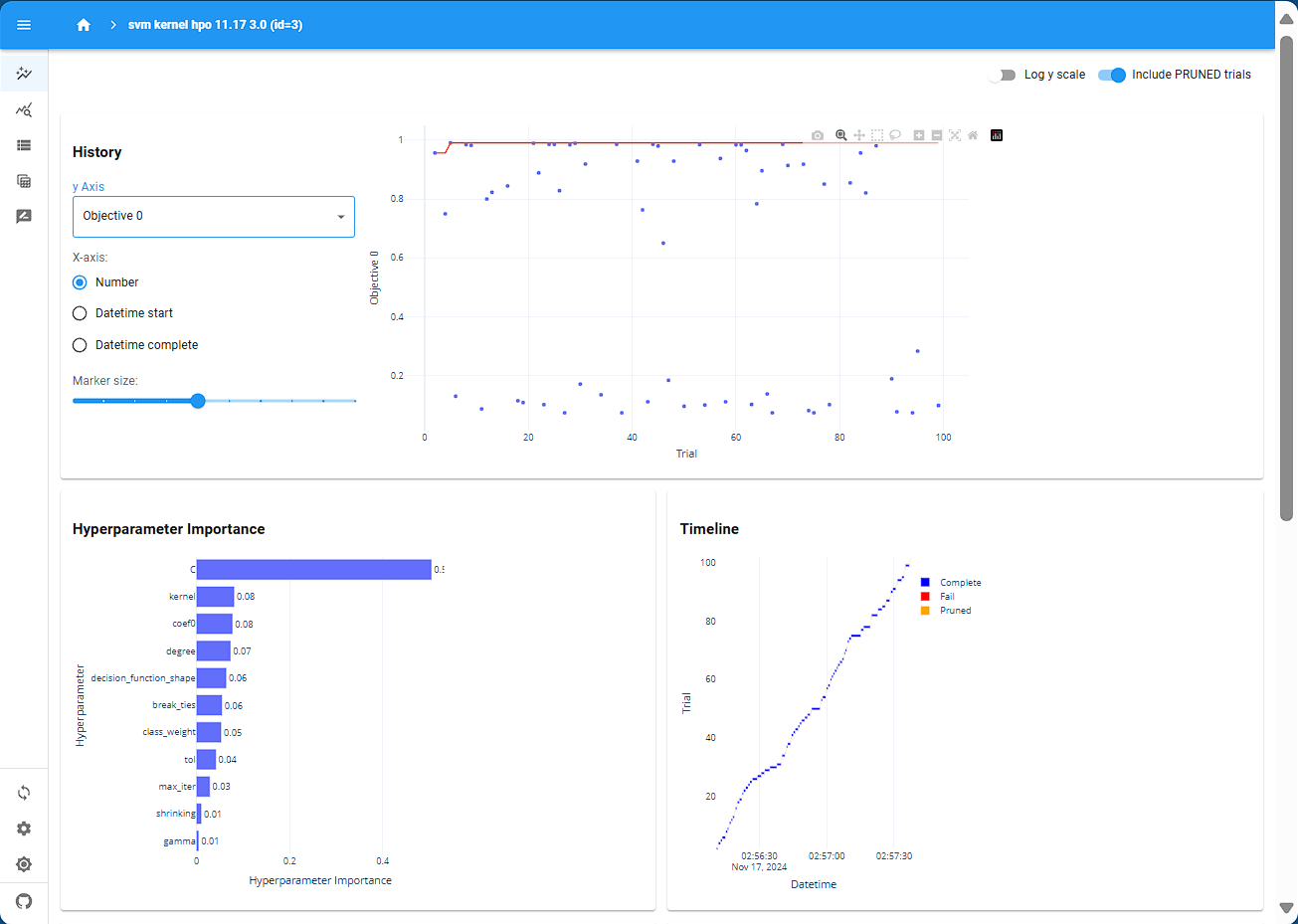
def objective_svm(trial:optuna.Trial, X_train_val, y_train_val, num_of_repeated=5, critical_metric="acc1_pred", critical_reduction="mean"): config:SupportVectorClassifierConfig = SupportVectorClassifierConfig.optuna_suggest( trial, fixed_meta_params, frozen_rvs=frozen_rvs)try: cross_val_results = evaluate_svm(config, X_train_val, y_train_val, trial=trial, critical_metric=critical_metric, num_of_repeated=num_of_repeated) critical_metric_name =f"{critical_metric}-{critical_reduction}" critical_result = cross_val_results[critical_metric_name]exceptValueErroras e:# logger.exception(e) logger.warning(f"Trial {trial.number} failed with error: {e}, we consider this as a pruned trial since we believe such failure is due to the implicit constraints of the problem. ")raise optuna.exceptions.TrialPruned()return critical_result
ExperimentalWarning:
QMCSampler is experimental (supported from v3.0.0). The interface can change in the future.
<ipython-input-1-ad5a12a62694>:6: ExperimentalWarning:
WilcoxonPruner is experimental (supported from v3.6.0). The interface can change in the future.
intersted_cols = [c for c in df.columns if c.startswith("params") or"user_attrs"in c or c=="value"]# intersted_cols = [c for c in df.columns if c.startswith("params") or c=="value"]dfi = df[intersted_cols].dropna(subset=[target])dfi.head()
value
params_C
params_break_ties
params_class_weight
params_coef0
params_decision_function_shape
params_degree
params_gamma
params_kernel
params_max_iter
...
user_attrs_precision-run1
user_attrs_precision-run2
user_attrs_precision-run3
user_attrs_precision-run4
user_attrs_recall-mean
user_attrs_recall-run0
user_attrs_recall-run1
user_attrs_recall-run2
user_attrs_recall-run3
user_attrs_recall-run4
2
0.956165
0.004186
True
None
0.708073
ovr
1.0
scale
linear
182.0
...
0.947915
0.961807
0.957685
0.964761
0.956196
0.951926
0.954759
0.954058
0.958502
0.961732
4
0.749492
0.031623
False
None
0.500000
ovr
5.0
scale
rbf
499.0
...
0.801343
0.839718
0.859636
0.849986
0.761556
0.733830
0.775699
0.789870
0.766079
0.742302
5
0.990258
1.778279
False
None
0.250000
ovo
3.0
auto
poly
750.0
...
0.985863
0.988889
0.981481
1.000000
0.989942
0.991154
0.986591
0.989747
0.982219
1.000000
6
0.130139
0.000562
False
balanced
0.750000
ovr
8.0
scale
sigmoid
249.0
...
0.013542
0.010105
0.010453
0.038927
0.120000
0.100000
0.100000
0.100000
0.100000
0.200000
8
0.984688
13.335214
False
balanced
0.125000
ovo
9.0
scale
linear
875.0
...
0.990013
0.982012
0.975091
0.993521
0.984161
0.982063
0.988435
0.981054
0.975855
0.993398
5 rows × 55 columns
import matplotlib.pyplot as pltimport seaborn as sns
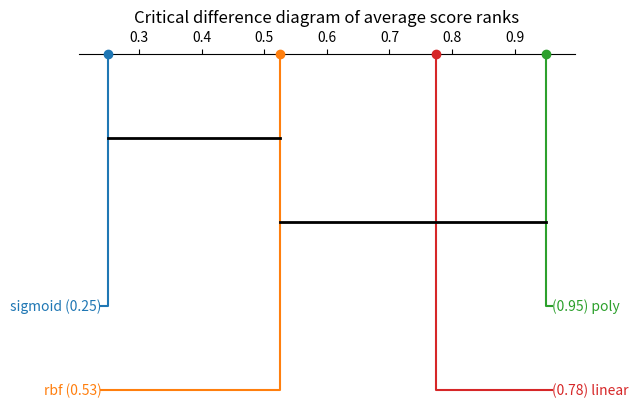
res = auto_kruskal_for_df(dfi, interesting_col=target, hue_col=treatment)if res.pvalue <0.05:print("There is a significant difference between the kernel functions.")res
Sun 2024-12-01 22:26:57.502502
INFO There is a significant difference between the kernel functions. nucleus.py:53
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.